import torch
inputs = torch.tensor(
[[0.43, 0.15, 0.89],
[0.55, 0.87, 0.66],
[0.57, 0.85, 0.64],
[0.22, 0.58, 0.33],
[0.77, 0.25, 0.10],
[0.05, 0.80, 0.55]]
)Attention Mechanism from Scratch — Exercises
First proposed in the Neural Machine Translation by Jointly Learning to Align and Translate paper, and later popularized by the Transformer paper, the Attention mechanism has become the backbone of most large language models today.
The goal of the attention mechanism is to compute a context vector for each input element that combines information from all other input elements.
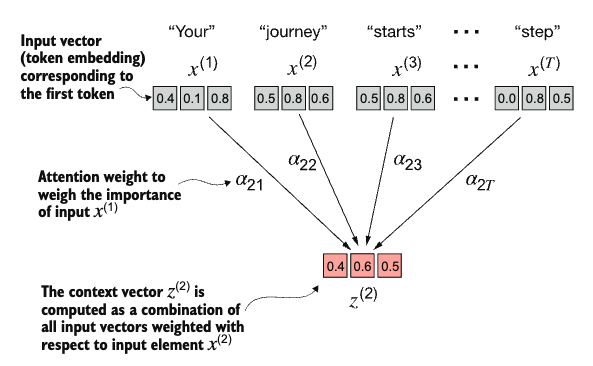
1. Calculating the Attention Scores
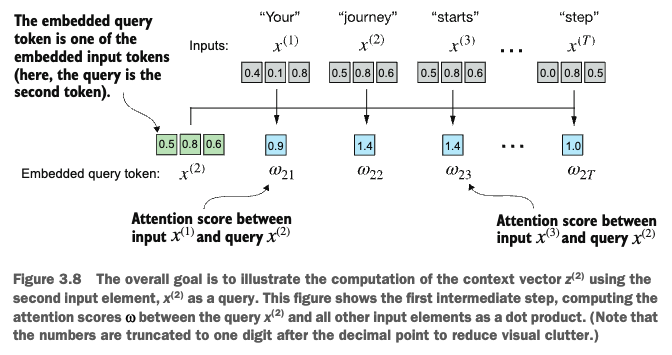
query = inputs[1]
attn_scores_2 = torch.empty(inputs.shape[0])
for i, x_i in enumerate(inputs):
attn_scores_2[i] = ___
print(attn_scores_2)2. Normalizing the Attention Scores
attn_weights_2_tmp = ___ / ___
print(attn_weights_2_tmp)
print(attn_weights_2_tmp.sum())def softmax(x):
return ___ / ___.sum()
attn_weights_2 = softmax(attn_scores_2)
print(attn_weights_2)attn_weights_2 = torch.___(attn_scores_2, dim=0)
print(attn_weights_2)
print(attn_weights_2.sum())3. Computing the Context Vector
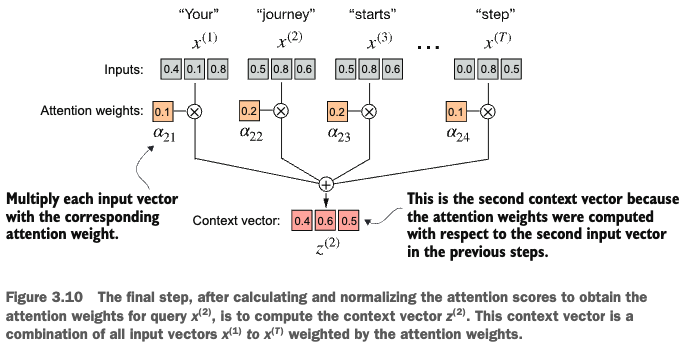
context_vec_2 = torch.zeros_like(query)
for i, x_i in enumerate(inputs):
context_vec_2 += ___ * ___
print(context_vec_2)4. Attention for All Tokens
attn_scores = ___ @ ___.T
attn_weights = torch.___(attn_scores, dim=-1)
all_context_vecs = ___ @ ___
print(all_context_vecs)5. Self-Attention with Trainable Weights

x_2 = inputs[1]
d_in = inputs.shape[1]
d_out = 2
torch.manual_seed(123)
W_query = torch.nn.Parameter(torch.randn(d_in, d_out), requires_grad=False)
W_key = torch.nn.Parameter(torch.randn(d_in, d_out), requires_grad=False)
W_value = torch.nn.Parameter(torch.randn(d_in, d_out), requires_grad=False)query_2 = ___ @ ___
key_2 = ___ @ ___
value_2 = ___ @ ___
print(query_2)keys = ___ @ ___
values = ___ @ ___
print(keys.shape, values.shape)6. Scaled Dot-Product Attention
attn_scores_2 = query_2 @ ___.T
d_k = keys.shape[-1]
attn_weights_2 = torch.___(___ / (d_k ** 0.5), dim=-1)
context_vec_2 = attn_weights_2 @ ___
print(context_vec_2)7. Self-Attention Class
import torch.nn as nn
class SelfAttentionv1(nn.Module):
def __init__(self, d_in, d_out):
super().__init__()
self.W_query = nn.Parameter(torch.randn(d_in, d_out))
self.W_key = nn.Parameter(torch.randn(d_in, d_out))
self.W_value = nn.Parameter(torch.randn(d_in, d_out))
def forward(self, x):
keys = x @ ___
values = x @ ___
queries = x @ ___
attn_scores = ___ @ ___.T
attn_weights = torch.___(attn_scores / (keys.shape[-1] ** 0.5), dim=-1)
context_vecs = ___ @ ___
return context_vecssa_v1 = SelfAttentionv1(d_in, d_out)
print(sa_v1(inputs))